Python - 面试题 (笔试)
一行代码实现求 1 - 100 的和
1 | # 利用sum(求和函数) |
列出 5 个 Python 标准库
1 | 1. os: 提供了不少与操作系统相关联的函数 |
列表 [1,2,3,4,5],请使用 map() 函数输出 [1,4,9,16,25],并使用列表推导式提取出大于 10 的数,最终输出 [16,25]
1 | l = [1, 2, 3, 4, 5] |
Python 中生成随机整数、随机小数、0 - 1 之间小数的方法
1 | import random |
避免转义给字符串加哪个字母表示原始字符串
1 | r,表示需要原始字符串,不转义特殊字符 |
a=(1,),b=(1),c=("1") 分别是什么类型的数据?
1 | a = (1,) |
列表推导式求列表所有奇数并构造新列表,a = [1,2,3,4,5,6,7,8,9,10]
1 | a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
filter 方法求出列表所有奇数并构造新列表,a = [1,2,3,4,5,6,7,8,9,10]
1 | a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
两个列表 [1,5,7,9] 和 [2,2,6,8] 合并为 [1,2,2,5,6,7,8,9]
1 | # 方法一 |
x="abc",y="def",z=["d","e","f"], 分别求出 x.join(y) 和 x.join(z) 返回的结果
1 | x = "abc" |
[[1,2],[3,4],[5,6]] 一行代码展开该列表,得出 [1,2,3,4,5,6]
1 | l = [[1, 2], [3, 4], [5, 6]] |
请列出你会的任意一种统计图(条形图、折线图等)绘制的开源库,第三方也行
1 | pychart、matplotlib |
[1,2,3]+[4,5,6] 的结果是多少?
1 | l1 = [1, 2, 3] |
a="hello" 和 b="你好" 编码成 bytes 类型
1 | a = b"hello" |
a="张明98分",用 re.sub,将 98 替换为 100
1 | import re |
python 中交换两个数值
1 | a, b = 2, 3 |
提高 python 运行效率的方法
- 使用生成器,因为可以节约大量内存
- 循环代码优化,避免过多重复代码的执行
- 核心模块用 Cython 和 PyPy 等,提高效率
- 多进程、多线程、协程
- 多个 if elif 条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率
使用 pop 和 del 删 "name" 字段,dic={"name":"zs","age":18}
1 | d1 = {"name": "zs", "age": 18} |
lt=[2,3,5,4,9,6],从小到大排序,不许用 sort,输出 [2,3,4,5,6,9]
1 | # 冒泡排序 |
int("1.4"),int(1.4) 输出结果?
1 | int("1.4") |
写正则
要求:匹配 6-10 位的密码,密码必须包括大写字母、小写字母和数字三种中的两种或两种以上
1
2
3
4
5
6
7
8
9
10
11import re
while 1:
string = input('请输入密码:')
pattern = re.compile('^(?![0-9]+$)(?![A-Z]+$)(?![a-z]+$)[0-9A-Za-z]{6,10}$')
pwd = pattern.search(string)
if pwd:
print('密码符合规范')
print(pwd.group())
else:
print('密码不合规范')要求:在一串随机字符串中匹配其中的年月日,如:fakjjh2005fa
2005年3月18日faldFh19951
2
3
4
5
6
7
8
9import re
string = 'fakjjh2005fa2005年3月18日faldFh1995'
pattern = re.compile('\d{4}年\d{1,2}月\d{1,2}日')
data = pattern.search(string)
if data:
print(data.group())
else:
print('没有匹配到')匹配 url
1
2
3
4
5
6
7
8
9
10
11
12
13import re
s = '''https://suyin-blog.club/
http://suyin-tools.cn/
https://suyin-blog.club/2019/3NSPBB9/?highlight=%E6%AD%A3%E5%88%99
https://image.baidu.com/search/detail?ct=503316480&z=0&ipn=false
www.chsi.com.cn/xlcs
本次招聘采用网上报名方式(http://rczp.hsbank.com.cn:8000/job/Info/422503)
http://rsj.beijing.gov.cn/ bjpta/
'''
if deal_url := re.findall(r'(?:https?(?::|:)//\s?|www)[A-Za-z0-9-./?%=&#:_\s]+', s):
for u in deal_url:
print(u)要求:匹配邮箱
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import re
s = '''suyin@nglm.onmicrosoft.com
22442550152@qq.com
suyin_long@163.com
zlx.suyin@gmail.com
jn15168896730@gmail.com
suyin-tools_123.sdaf@outlook.com
Email: yhemar@szu.edu.cn
47366775@qq.com
zhangbohan@jlu.edu.cn
'''
if mail := re.findall(r'[-(?:A-Za-z0-9)_.]+(?:@|@)[-A-Za-z0-9]+(?:\.[A-Za-z0-9]+)+', s):
for m in mail:
print(m)要求:匹配手机号
1
2
3
4电信号码段:133、149、153、173、177、180、181、189、199
移动号码段:134、135、136、137、138、139、147、150、151、152、157、158、159、178、182、183、184、187、188、198
联通号码段:130、131、132、145、155、166、175、176、185、186
虚拟运营商:1700、1701、1702 1703、1705、1706 1704、1707、1708、1709手机号主要验证的是前面 3 位数,也就是它的号段,所以我们可以相应去写匹配它的正则表达式
1
2
3
4
5
6
7
8
9
10import re
while 1:
phone_number = input('请输入手机号:')
pattern = re.compile(r'^((13[0-9])|(14[5,7,9])|(15[0-3,5-9])|(17[0,3,5-8])|(18[0-9])|166|198|199)\d{8}$')
m = pattern.search(phone_number)
if m:
print('手机号格式正确!')
else:
print('手机号格式错误!')13 [0-9] 匹配所有 13,(14 [5,7,9]) 匹配 145、147、149,(15 [0-3,5-9]) 匹配 15 (03) 15 (59),就是除了 154,都可以匹配到 15,(17 [0,3,5-8]) 匹配 170、173、175、176、177、178,(18 [0-9]) 匹配所有 18*,还有其他 166/198/199,然后就是后面的 8 位数,这里就是 \d 匹配数据 8 次
匹配所有电话号 (固话 + 手机号)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import re
s = '''咨询电话:0551-65283356
监督电话:0551-65283184
2528318
报名系统技术电话:0551-62891910
0558--7622434、7692075
联系电话:13695313878
19995313878
061-81337(路内),028-86481337(路外)
监督(举报)电话:021-65670070/65674661
联系电话:13558639992
招聘平台系统操作咨询:4001095598
0874―3131093
'''
if phone := re.findall(r'1[3-9]\d{9}|400\d{7}|0\d{2,3}[\s—-―-]+[2-8]\d{4,7}|[2-8]\d{6,7}', s):
for p in phone:
print(p)中国大陆的固定电话号码为 7 位或 8 位数字(不含区号和冠码),第一位数字为 2-8,其它数字为 0-9。区号以 0 开头。
中国邮政使用由六位数字组成的四级邮政编码。
不使用内置 api,例如 int(), 将字符串 "123" 转换成 123
方法一:利用
str函数1
2
3
4
5
6
7def atoi(s):
num = 0
for v in s:
for j in range(10):
if v == str(j):
num = num * 10 + j
return num方法二:利用
ord函数1
2
3
4
5def atoi(s):
num = 0
for v in s:
num = num * 10 + ord(v) - ord('0')
return num方法三:利用
eval函数1
2
3
4
5
6
7def atoi(s):
num = 0
for v in s:
t = "%s * 1" % v
n = eval(t)
num = num * 10 + n
return num方法四:结合方法二,使用
reduce,一行解决1
2
3from functools import reduce
def atoi(s):
return reduce(lambda num, v: num * 10 + ord(v) - ord('0'), s, 0)
请反转字符串 "abcd"?
1 | "abcd"[::-1] |
请将字典 d={'a':23,'g':55,'i':10,'k':37} 按 value 值进行排序
1 | d = {'a': 23, 'g': 55, 'i': 10, 'k': 37} |
编写程序,查找文本文件中最长的单词
1 | def longest_word(filename): |
编写程序,检查序列是否为回文
1 | a = input("Enter The sequence") |
编写程序,打印斐波那契数列的前十项
1 | # 斐波那契数列指的是这样一个数列:1,1,2,3,5,8,13,21,34,55,89... |
编写程序,计算文件中单词的出现频率
1 | from collections import Counter |
编写程序,输出给定序列中的所有质数
1 | lower = int(input("Enter the lower range:")) |
编写程序,检查数字是否为 Armstrong
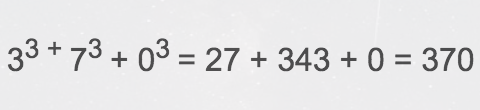
将每个数字依次分离,并累加其立方 (位数)。最后,如果发现总和等于原始数,则称为阿姆斯特朗数 (Armstrong)。
1 | num = int(input("Enter the number:\n")) |
用一行 Python 代码,从给定列表中取出所有的偶数和奇数
1 | a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
将列表去重,去重后的列表中元素的位置不变
1 | lt = [3, 7, 2, 2, 5, 3, 8, 9, 1, 1, 8] |