爬虫 - 多线程爬虫
引入
多任务,多个任务同时进行,如何解决该问题?(2 种方式)
1 | import time |
- 多进程:电脑上同时打开 sublime、录屏、vnc 服务器
- 多线程:
- 在 word 文档中同时编辑、检查(多线程)
- 在 qq 中同时语音、视频、发送消息(多线程)
创建线程 Thread (2 种方式)
面向过程
1
2
3
4
5
6
7t = threading.Thread(target=xxx, name=xxx, args=(xx, xx))
target: 线程启动之后要执行的函数
name: 线程的名字
获取线程名字: threading.current_thread().name
args: 主线程向子线程传递参数
t.start(): 启动线程
t.join(): 让主线程等待子线程结束1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38import time
import threading
def sing(a):
print(f'线程为:{threading.current_thread().name};接收过来的参数为:{a}')
for x in range(1, 6):
print('我在唱舞娘')
time.sleep(1)
def dance(b):
print(f'线程为:{threading.current_thread().name};接收过来的参数为:{b}')
for x in range(1, 6):
print('我在跳钢管舞')
time.sleep(1)
# 一个主线程、两个子线程(唱歌线程、跳舞线程)
def main():
a, b = '孙悟空', '猪八戒'
# 创建唱歌线程
tsing = threading.Thread(target=sing, name='唱歌', args=(a,))
# 创建跳舞线程
tdance = threading.Thread(target=dance, name='跳舞', args=(b,))
# 启动线程
tsing.start()
tdance.start()
# 让主线程等待子线程结束之后在结束
tsing.join()
tdance.join()
# 这里是主线程在运行
print(f'这里是主线程:{threading.current_thread().name}')
if __name__ == '__main__':
main()面向对象
定义一个类,继承自
threading.Thread,重写一个方法run方法,需要线程名字、传递参数,重写构造方法,在重写构造方法的时候,一定要注意手动调用父类的构造方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51import time
import threading
# 写一个类,继承自threading.Thread
class SingThread(threading.Thread):
def __init__(self, name, a):
super().__init__()
self.name = name
self.a = a
def run(self):
print(f'线程的名字是:{self.name},接收过来的参数为:{self.a}')
for x in range(1, 6):
print('我在唱七里香')
time.sleep(1)
class DanceThread(threading.Thread):
def __init__(self, name, b):
super().__init__()
self.name = name
self.b = b
def run(self):
print(f'线程的名字是:{self.name},接收过来的参数为:{self.b}')
for x in range(1, 6):
print('我在跳广场舞')
time.sleep(1)
def main():
a, b = '孙悟空', '猪八戒'
# 创建线程
tsing = SingThread('唱歌', a)
tdance = DanceThread('跳舞', b)
# 启动线程
tsing.start()
tdance.start()
# 让主线程等待子线程结束后再结束
tsing.join()
tdance.join()
print('主线程和子线程全部结束!')
if __name__ == '__main__':
main()
线程同步
- 线程之间共享全局变量,很容易发生数据的紊乱问题,这个时候要使用线程锁;抢,谁抢到,谁先上锁,上锁之后,谁就先使用
- 创建锁:
suo = threading.Lock() - 上锁:
suo.acquire() - 释放锁:
suo.release()
队列 (queue)
- 下载线程
- 解析线程,通过队列进行交互
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 创建对列
q = Queue(5)
# 存储数据
q.put('xxx') 如果队列已满,程序卡在这里等待
q.put(xxx, False) 如果队列已满,程序直接报错
q.put(xxx, True, 3) 如果队列已满,程序等待3s再报错
# 取数据,先进先出
q.get() 如果队列为空,程序卡在这里等待
q.get(False) 如果队列为空,程序直接报错
q.get(True, 3) 如果队列为空,程序等待3s报错
q.empty() 判断队列是否为空
q.full() 判断队列是否已满
q.qsize() 获取队列长度 - 示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36from queue import Queue
def main():
# 创建对列
q = Queue(5)
# 判断队列是否为空
print(q.empty()) # True
# 存储数据
q.put('科比')
q.put('勒布朗')
q.put('JR')
q.put('汤普森')
# 获取队列长度
print(q.qsize()) # 4
q.put('love')
# 判断队列是否已满
print(q.full()) # True
# 如果队列已满,程序等待3s再报错
# q.put('乔治希尔', True, 3) # queue.Full
print(q)
# 取数据,先进先出
print(q.get())
print(q.get())
print(q.get())
print(q.get())
print(q.get())
# 如果队列为空,程序等待3s报错
# print(q.get(True, 3)) # queue.Empty
if __name__ == '__main__':
main()
分析
- 两类线程:下载(3)、解析(3)
- 内容队列:下载线程往队列中 put 数据,解析线程从队列 get 数据
- url 队列:下载线程从 url 队列 get 数据
- 写数据:上锁
图示
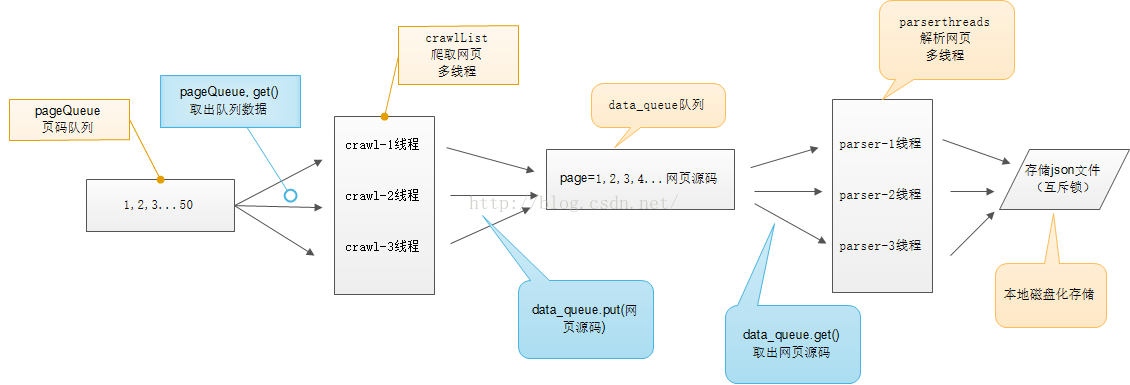
示例:爬取贱图
1 | import time |