Crawlab v0.5.x 使用教程(Python)
- Crawlab是基于Golang的分布式爬虫管理平台,支持多种编程语言以及多种爬虫框架。
- 本教程是针对Python用户来写的一份Crawlab简单上手指南!
- 另外附上 宝塔下安装 Crawlab 教程,有需要的可以看一看!
- 如果还有什么不懂得也可以参考Crawlab官网文档!
通用Python爬虫脚本(单文件)的使用教程
-
添加代码
1
2
3
4
5
6
7
8# 引入保存结果方法
from crawlab import save_item
# 这是一个结果,需要为 dict 类型
result = {'name': 'crawlab'}
# 调用保存结果方法
save_item(result)将以上代码加入到您爬虫中的结果保存部分。
-
添加依赖文件
- 如果您脚本中用到了Crawlab默认没有安装的依赖包,你需要手动新建依赖文件
requirements.txt,如果您不需要另外的依赖,则不用新建requirements.txt文件 - 将您项目运行时必须的且 Crawlab 默认没有安装的依赖包添加到
requirements.txt中,如:jsonpath==0.82 - ⚠️注意:依赖包必须指定版本,否则无法安装
- Crawlab 会自动扫描代码目录,如果存在
requirements.txt,就会自动执行对应的安装程序,将指定的依赖安装到 Crawlab 节点上 - Crawlab默认安装的依赖项
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45attrs
automat
beautifulsoup4
bs4
certifi
cffi
chardet
click
constantly
crawlab-sdk
cryptography
cssselect
elasticsearch
hyperlink
idna
incremental
itemadapter
itemloaders
jmespath
kafka-python
lxml
parsel
pathspec
prettytable
protego
psycopg2-binary
pyasn1
pyasn1-modules
pycparser
pydispatcher
pyhamcrest
pymongo
pymysql
pyopenssl
queuelib
requests
scrapy
scrapy-splash
service-identity
six
soupsieve
twisted
urllib3
w3lib
zope.interface
- 如果您脚本中用到了Crawlab默认没有安装的依赖包,你需要手动新建依赖文件
-
打包为 Zip 文件
- 在通过Web界面上传之前,需要将爬虫项目文件打包成
zip格式 - ⚠️注意:如果您在上一步新建了依赖文件
requirements.txt,打包的时候需要将其一起打包
- 在通过Web界面上传之前,需要将爬虫项目文件打包成
-
上传爬虫文件
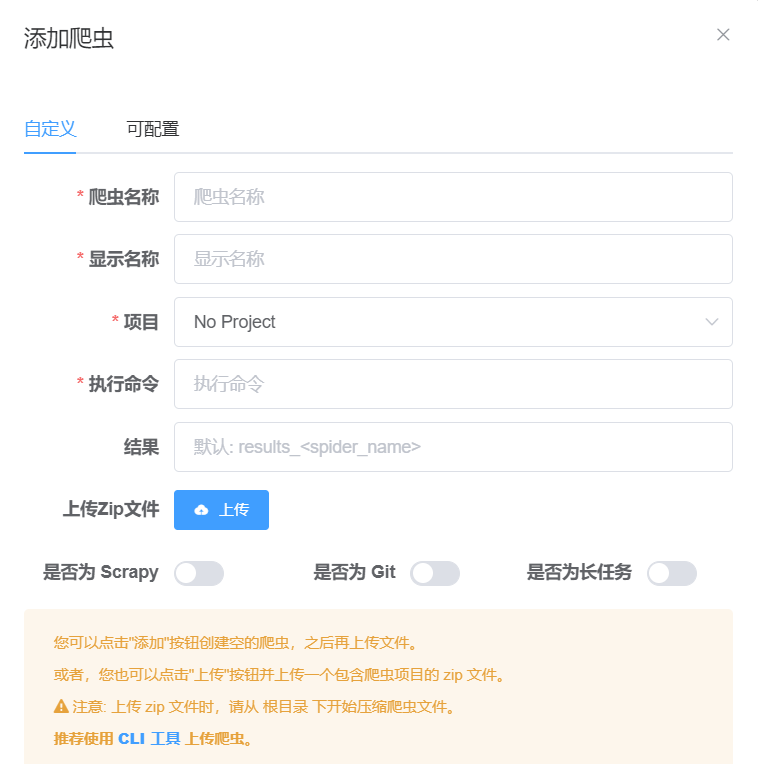
- 首先,您需要导航到爬虫列表页,然后点击【添加爬虫】
![]()
- 选择【自定义爬虫】(默认),将出现以下界面
![]()
- 输入相应的参数:【爬虫名称】、【显示名称】、【项目】(如果没有项目可留空)、【执行命令】和【结果】
- 它们的定义如下:
- 爬虫名称:爬虫的唯一识别名称,将会在爬虫根目录中创建一个该名称的文件目录,因此建议为没有空格和特殊符号的 小写英文,可以带 下划线
- 显示名称:爬虫显示在前端的名称,可以为任何字符串(如:中文等)
- 项目:爬虫所属的项目,没有所属项目可以留空
- 执行命令:爬虫将在 shell 中执行的命令,最终被执行的命令将为
执行命令和参数的组合 - 结果:【结果集】的意思,爬虫抓取结果储存在 MongoDB 数据库里的集合(Collection),类似于 SQL 数据库中的表(Table)
- 首先,您需要导航到爬虫列表页,然后点击【添加爬虫】
-
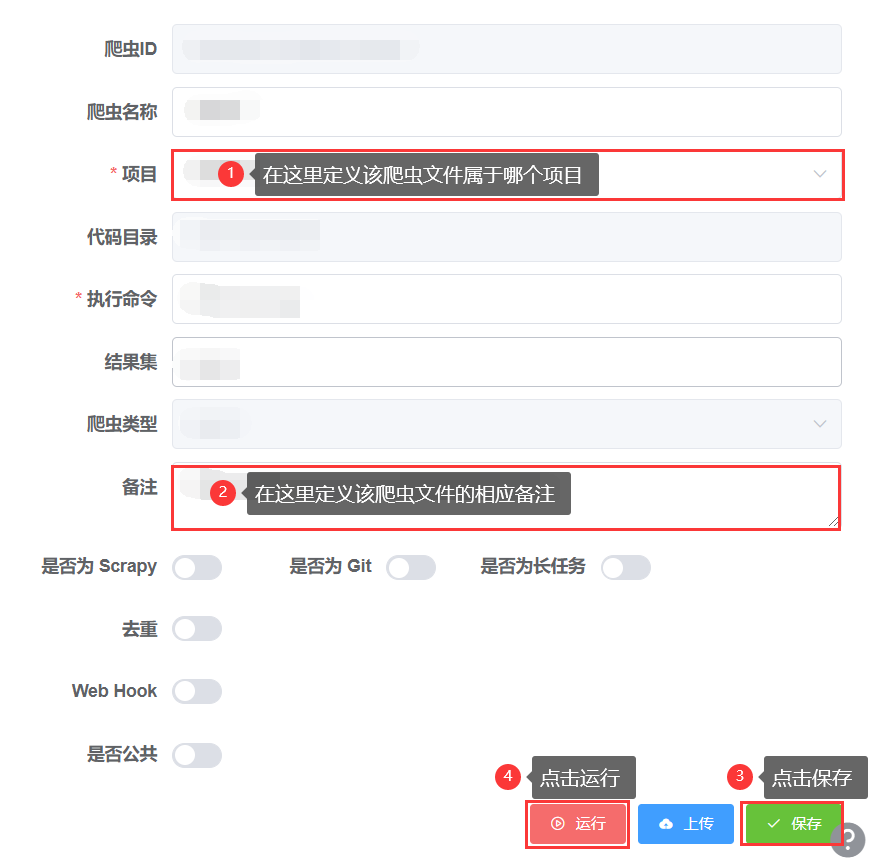
运行爬虫文件
- 上传完爬虫文件后,会跳转到爬虫详情页,在这里你可以修改该爬虫文件的一些详细信息,如:项目、备注等等
- 修改完后,点击【保存】,最后点击【运行】,即可运行项目,开始抓取数据
![]()
-
查看结果集
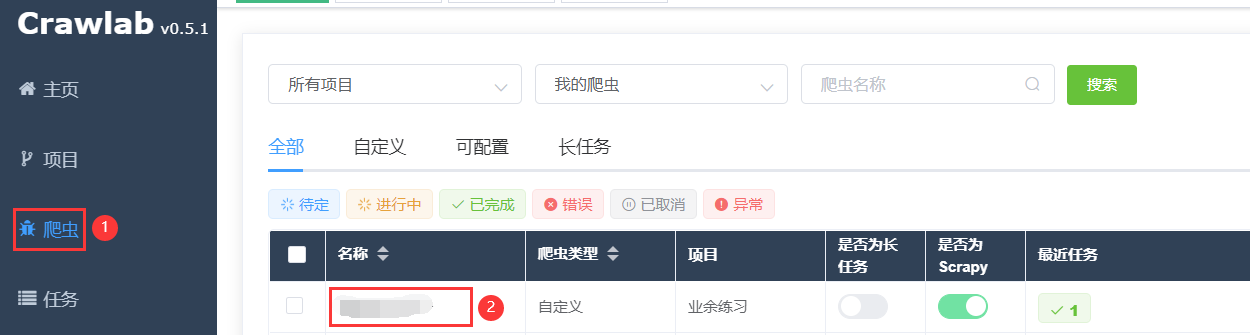
- 在爬虫列表页点击运行过的爬虫名称,进入【爬虫详情页】
![]()
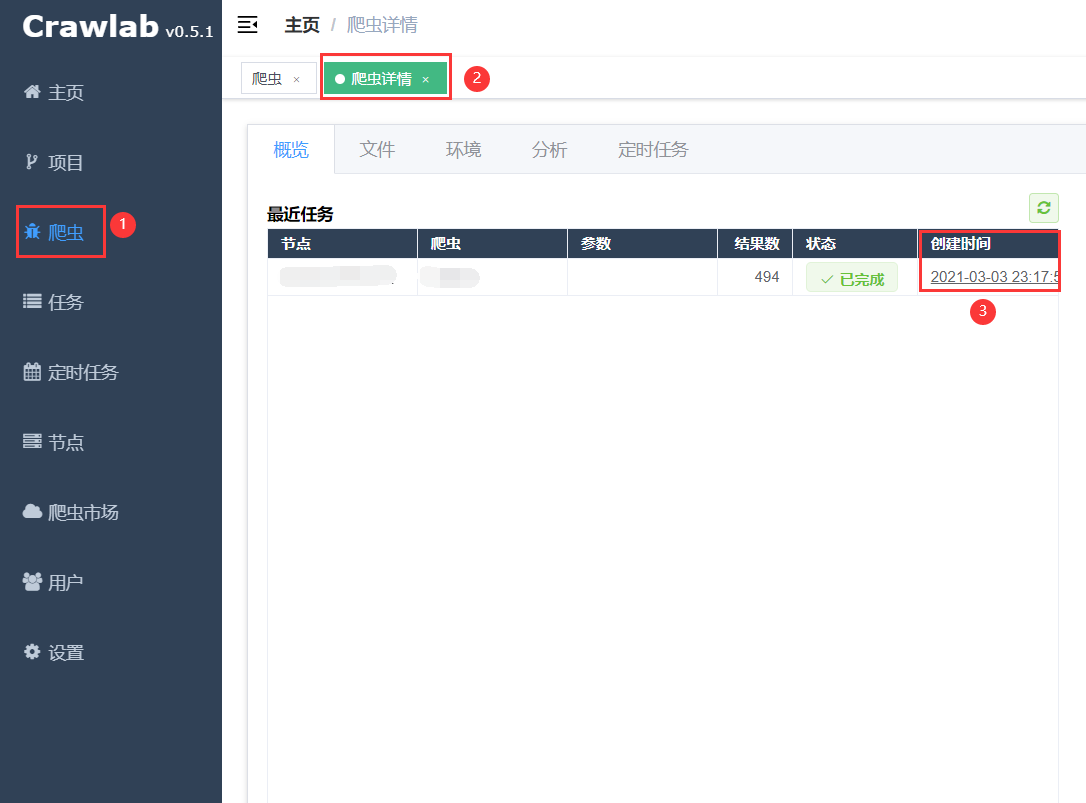
- 在【爬虫详情页】点击【创建时间】,进入【任务详情页】
![]()
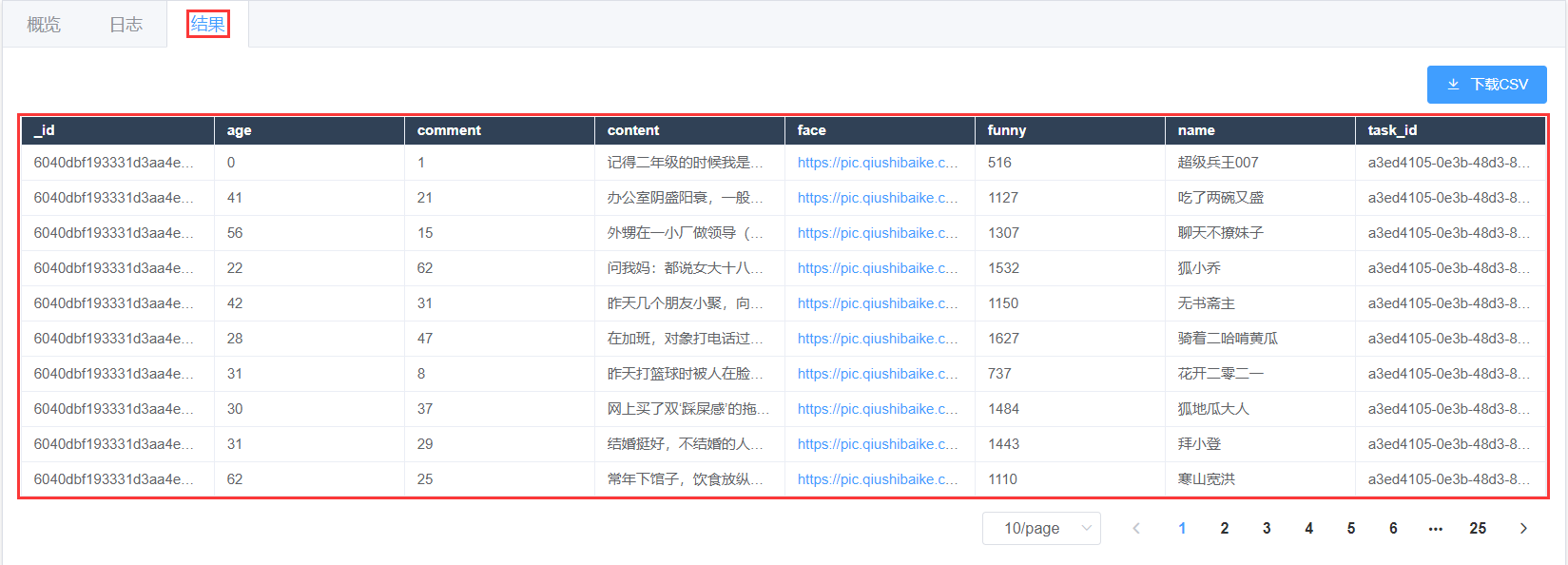
- 在【任务详情页】查看运行【结果】,同时还可以查看【日志】和【概览】
![]()
- 你也可以使用Robo 3T等工具连接数据库,查看数据集
- 在爬虫列表页点击运行过的爬虫名称,进入【爬虫详情页】

-
修改配置文件
- 在
settings.py中找到ITEM_PIPELINES(dict类型的变量),在其中添加如下内容1
2
3ITEM_PIPELINES = {
'crawlab.pipelines.CrawlabMongoPipeline': 888,
}
- 在
-
添加依赖文件
- 如果您的Scrapy爬虫项目中用到了 Crawlab 默认没有安装的依赖包,你需要手动在Scrapy项目目录中新建依赖文件
requirements.txt,如果您不需要另外的依赖,则不用新建requirements.txt文件 - 将您项目运行时必须的且 Crawlab 默认没有安装依包添加到
requirements.txt中,如:jsonpath==0.82
- 如果您的Scrapy爬虫项目中用到了 Crawlab 默认没有安装的依赖包,你需要手动在Scrapy项目目录中新建依赖文件
-
打包为 Zip 文件
- 在通过Web界面上传之前,需要将爬虫项目文件打包成
zip格式 - ⚠️注意:您需要在爬虫项目根目录下打包,意思是您需要进入到项目的第一层,将所有文件和文件夹打包成 zip 文件。
- 在通过Web界面上传之前,需要将爬虫项目文件打包成
-
上传爬虫文件
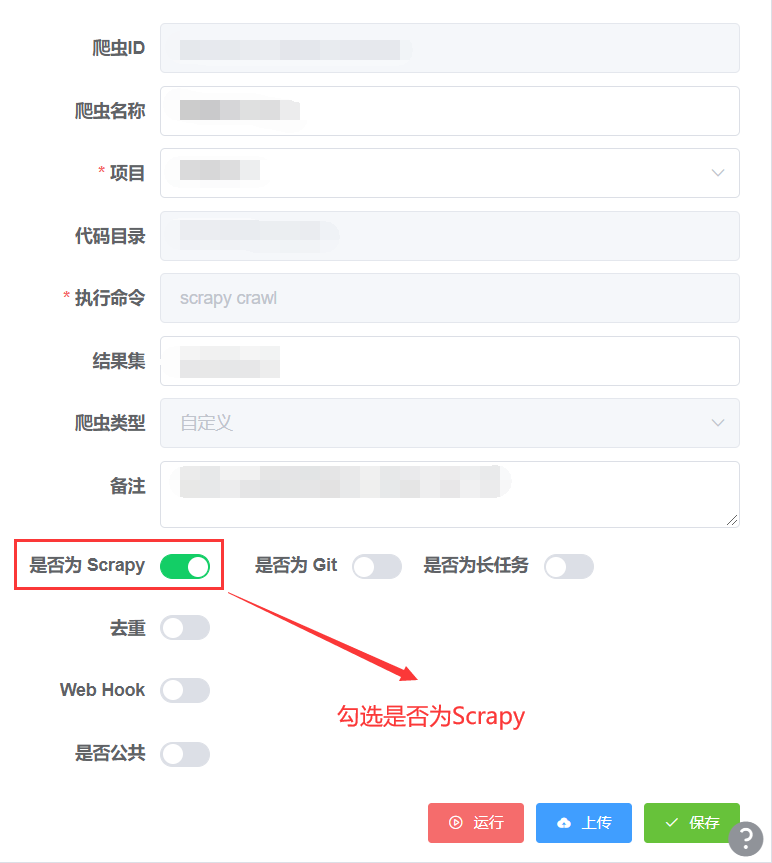
- 上传步骤同上,只需要在创建爬虫或修改爬虫时开启是否为 Scrapy,如图
![]()
- ⚠️注意:在开启这个选项前,请保证您的爬虫项目为一个 Scrapy 爬虫,最好的检测方式,就是检查您爬虫项目的根目录下是否有
scrapy.cfg文件。如果您的爬虫项目根目录没有scrapy.cfg文件,请尝试用 CLI 工具 上传您的 Scrapy 爬虫
- 上传步骤同上,只需要在创建爬虫或修改爬虫时开启是否为 Scrapy,如图
-
设置Scrapy
-
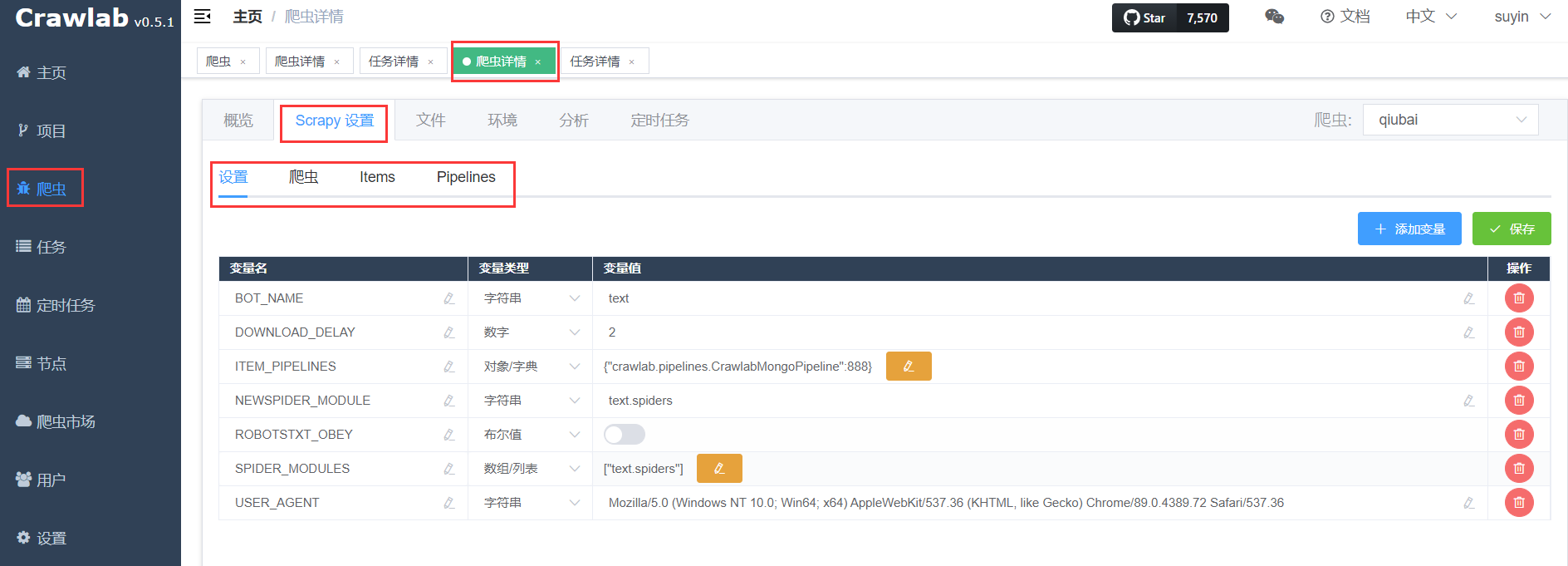
如果上传成功,您将看到爬虫详情里有
Scrapy 设置标签,点开标签您能看到如下界面
![]()
-
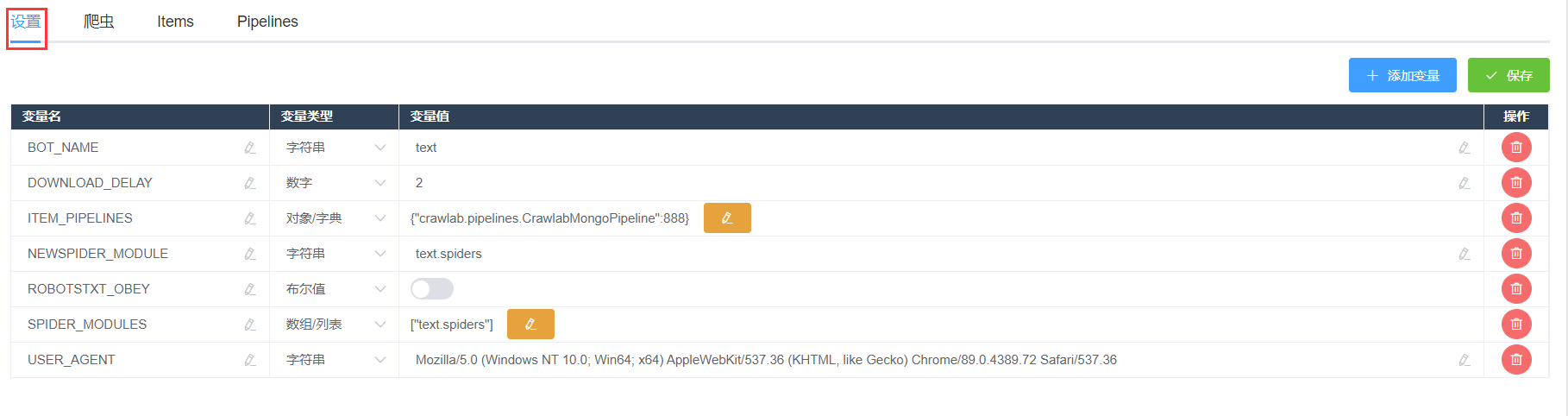
设置
- 第一个默认标签是【设置】,这是 Scrapy 爬虫的设置界面,也就是配置
settings.py的地方。Crawlab 会将您 Scrapy 爬虫项目中的settings.py中的变量读取并显示出来。在这里,您可以添加、删除修改任何settings.py中的变量。在修改变量时,别忘记确定变量类型。 - 点击【保存】按钮后,您的设置就保存在
settings.py里去了,您可以到【文件】标签中检查settings.py是否生效。
![]()
- 第一个默认标签是【设置】,这是 Scrapy 爬虫的设置界面,也就是配置
-
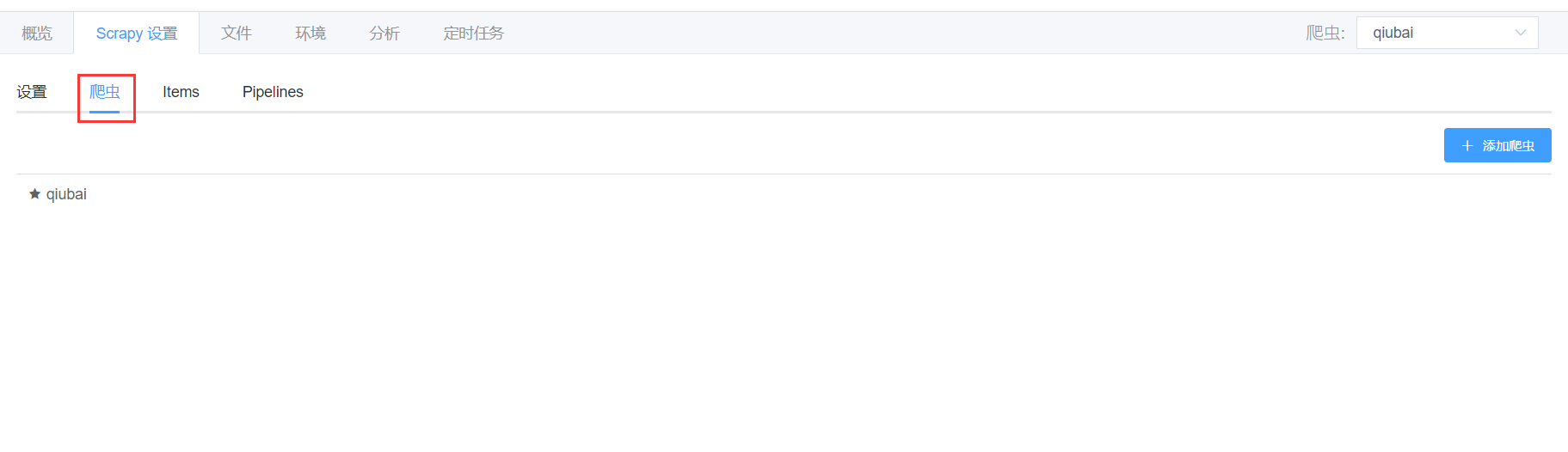
爬虫
- 第二个标签是【爬虫】,这是在
spiders文件夹里定义的爬虫,是继承了scrapy.Spider的类。 - 您可以点击【添加爬虫】来创建一个新的 Scrapy 爬虫,这相当于是执行了
scrapy genspider的操作。 - 同时,如果您点击 Scrapy 爬虫列表中的一个爬虫,可以自动跳转到对应的爬虫文件。
![]()
- 第二个标签是【爬虫】,这是在
-
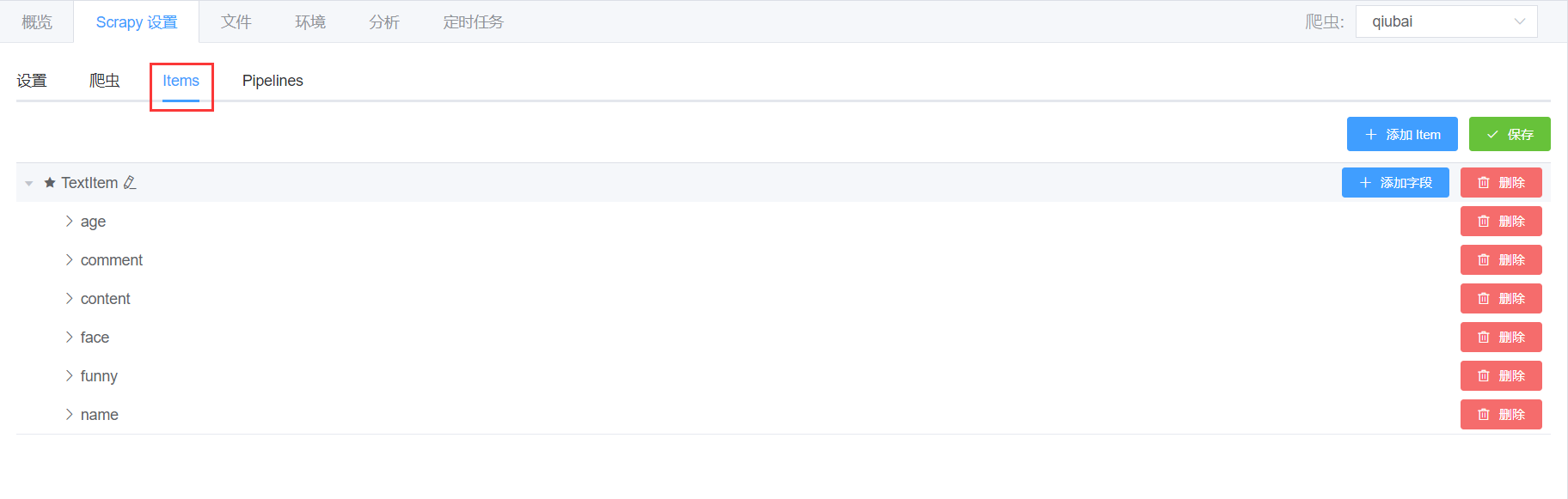
Items
- 第三个标签是【Items】,这里是定义爬虫抓取项的地方,会将
items.py中的继承了scrapy.Item的类以及其字段列表读取并展现出来,如下图。
![]()
- 在这里,您可以添加、删除以及修改
Item的字段。 - 点击【保存】按钮操作成功后,您将看到所修改的
Item并且字段已经在items.py中生效了。
- 第三个标签是【Items】,这里是定义爬虫抓取项的地方,会将
-
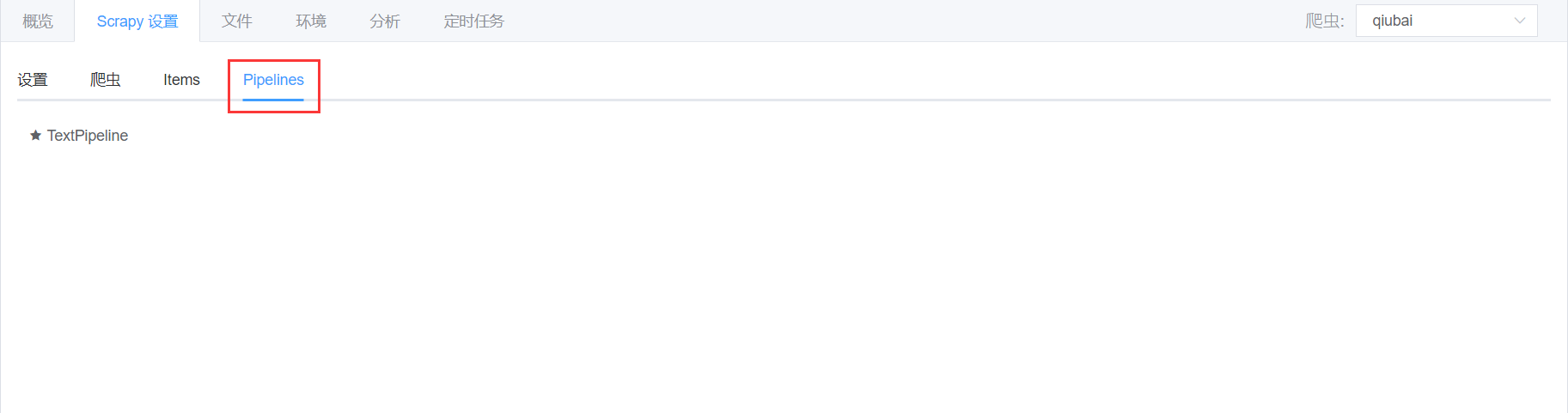
Pipelines
- 第四个标签是【Pipelines】,在这里您可以看到 Pipeline 的列表,点击之后跳转到
pipelines.py文件。
![]()
- 第四个标签是【Pipelines】,在这里您可以看到 Pipeline 的列表,点击之后跳转到
-
-
运行爬虫文件
- 运行爬虫文件步骤同上
-
查看结果集
- 查看结果集步骤同上